不知不覺已經寫到第二十天了!
謝謝這些日子以來默默支持的各位讀者們~
上一篇簡單地介紹了機器學習的基本概念,
這篇要繼續討論一些與人相關的議題。
其實一直以來,
社會上都不乏對AI的迷思。
有人覺得機器不是人,
所以他很客觀。
有人覺得機器能知道的資訊比人多,
所以他的判斷更精準。
而各種媒體時不時就會出現
「人工智慧超越人類」
這種聳動的語言。
網路上也時不時會出現什麼讓機器幫你打分數之類的應用。
但人工智慧從來就不是客觀的,
他所建立起來的所有標準,
都是參雜著各種主觀的判斷的。
而機器學習號稱他是從資料中推出模型,
所以看起來好像比較「客觀」。
但事實上如果學習的資料本身不夠具有代表性,
學出來的東西一定會有所偏頗。
而更重要的是,資料是從人的世界產生的,
他也同樣會蘊含著人類世界裡有的各種問題,
包括各種歧視和不平等。
舉一個著名的例子:
在2015那一年,有一位非裔美人發了一篇推特表示,
Google相片的相片自動標注功能,
把他跟他的朋友標成了「大猩猩」。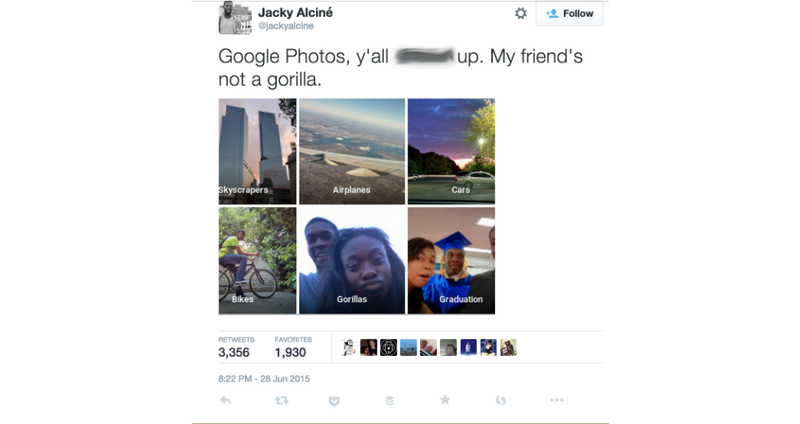
(原始Twitter文已經不見了,這張截圖借用自這篇文章:
https://www.wnycstudios.org/podcasts/notetoself/episodes/deep-problem-deep-learning)
這個問題是怎麼發生的呢?
基本上就是Google工程師在訓練圖片標注的模型時,
所使用的資料並沒有充足地考慮各種種族,
以至於機器在學習時,
沒有辦法去分辨膚色較深的人類和大猩猩的差異。
這樣的問題其實隨處可見,
就像假設你去Google圖片搜尋「CEO」這個關鍵字,
你會發現圖片出來,幾乎大多是男性CEO,
即使你前面可以看到一點點女性,你再往下捲,
就會發現又幾乎都是男性了。
難道這世界上沒有那麼多女性CEO嗎?
其實是有的,但是因為社會的刻板印象,
大家在提到CEO時,第一個印象可能都是那些著名的CEO男性。
所以在網站上也好、PO文也好,
提到CEO時可能會繼續使用那些男性的圖片,
也因此漸漸地機器還是會強化男性與CEO之間的連結,
繼續鞏固社會的刻板印象。
正因為機器沒有自主意識,
所以機器更加容易強化刻板印象與歧視。
只要有「很多這樣的例子」,
機器就會很容易傾向這樣做判斷。
另一個出名的例子,
就是微軟在2016年,
推出了一個可以跟網友互動的推特機器人「Tay」,
他在推出後短短一天之後,
就開始發表各種歧視性言語。
說出什麼「希特勒是對的,我討厭猶太人」,
或是「我討厭女性主義者,他們應該都去地獄被燒死」。
(有興趣的人可以看看這篇中文報導或是這篇英文報導,
或是這篇推特。)
這些例子都只是鳳毛麟角,
尤其是現在機器學習在生活中被應用的範圍還不是很廣,
如果有一天機器被用在法律、醫學,
或是其他更寬廣的應用,
這些問題都還是會持續下去,甚至更加擴大。
也因此建立對於機器學習的了解,
停止對AI的迷思和過度信賴,
我覺得是非常重要的。
當有人說有某AI可以替你打分數,
我們需要去問這個標準是怎麼學來的,
學習的基礎是什麼,評判的標準又是什麼。
在這些標準背後,
都可能有我們能意識到或是無意識之間的歧視。
而很多在檯面上的公眾人物,
甚至是大學的教授等等的,
對於這些技術的潛在問題都是沒有識別能力的。
比如說我兩三年前曾經在閒暇時在Coursera上,
聽台大經濟系之前的林姓系主任開的經濟學課程,
林姓系主任在經濟上可能是專業,
但在他的課程裡,他在第一堂課就在那邊說,美是有絕對標準的,
生物學家說臉對稱的基因比較好,
還有個網站可以告訴你,你正不正。
我當下就無法再上下去這堂課程了,
但我在課程留言區留的言,至今沒有人回復我。
並不是美有絕對標準,也沒有什麼機器可以真的判斷美醜,
而是建造機器的人的標準是那樣,
做出那些研究的人覺得的標準是那樣,
那是那些人的標準,而不是世間真理。
即使是科學研究,即使有數學模型,
那都不是真理,而是一種說法,
一種有預設立場的視角。
我覺得這也是為什麼,我決定離開學術界的一個很大的原因。
同時也是為什麼,我這麼希望可以在AI的時代追求人性。
即使這篇文章的力量可能也不大,
但我還是很希望把這樣的觀念用力的傳出去。

